All articles
Vision
·
·
6
min read
The Cost of Cheap Code

Our first weeks with Claude Code were rough. There was a week, pretty soon after we cut over, where nothing got merged.
Not nothing-nothing. Things slipped through here and there. But the main flow of meaningful work stalled out. PRs sat. Slack filled up with variations of “Hey folks, can we get some eyes on this PR? It’s been sitting for a couple of days.” People kept opening new ones anyway, because the tool made it so easy. By the end of the week we had a queue of “whales” - massive end-to-end PRs that any one of us could produce in an afternoon, and none of us could review in less than half a day. We’re a small team at Ewake. We shouldn’t have a backed-up PR queue.
The team’s productivity was down, but, individually, we each felt like we had never been more productive. Both were true, and this contradiction is what this post is about.
What did we do?
The simple and clean take here is “AI tools made writing code fast, so review became the bottleneck”. This isn’t exactly a hot take any more. The statement is true, but it’s shallow. The more honest version is that the cadence of the job is different now, and we need to adapt to it.
We thought we were in good shape. We had team principles, written down months earlier. Two of them are directly relevant right now:
Writing is cheaper than coding. We shape ideas and solve hard architectural problems before we open the editor.
Code is a liability. It only becomes an asset when it’s merged and validated. Keep branches short, optimise for integration.
We agreed on these, and would quote them at each other, but we’d never really stress tested them. The slowness of human typing had been doing a lot of invisible work, camouflaging the gap between our principles and our practices. It’s hard to accidentally knock out a 1500 line PR in an afternoon when you’re the one typing it.
When producing code got cheap, that cover was gone and the gap became visible. We weren’t sloppy and we hadn’t lowered our standards. We were a team whose review urgency and prioritisation had been propped up by something that had just disappeared. Claude Code load-tested our review cadence, and DoS-ed it.
Honestly, my first reaction was a few wobbly minutes of “should we just stop using this thing?” - but that passed quickly. The tool was good. We just needed to figure out how to keep up with it.
The Fixes
We changed our team behaviour first. We couldn’t fix this with tooling, but we could make the behavioural changes easier to live with.
Reviewer-first mindset: We agreed to shape PRs for the reviewer, not the writer. The natural shape of work coming out of an AI agent is “the whole thing, in one diff,” because that’s what’s easiest to produce. Easiest to produce is the opposite of easiest to review.
Stacked PRs: When a change does need to be large, we break it into a stack where context builds up gradually. PR 1 establishes the foundation, PR 2 reads with that context already loaded. We use Graphite for this. Doing it natively in GitHub is miserable work. More work for the author, significantly less for the reviewer. The right tradeoff when the reviewer is the constraint.
Unblocking over writing: If there are open PRs needing review, addressing them takes priority over starting new work. Not “drop tools the moment a PR opens,” but as a default ordering when choosing what to do next.
The “please break this up” agreement. Anyone can ask anyone else to take a PR down and split it. The author isn’t obligated, but in practice people are good about this. As we get used to our new reviewer-first mindset, this is coming up less and less.
Review SLAs. Defined for scope reviews, design reviews, and code reviews. Having a number to compare against takes the subjectivity out of “this PR has been sitting a while” and turns it into a concrete signal.
Press enter or click to view image in full size
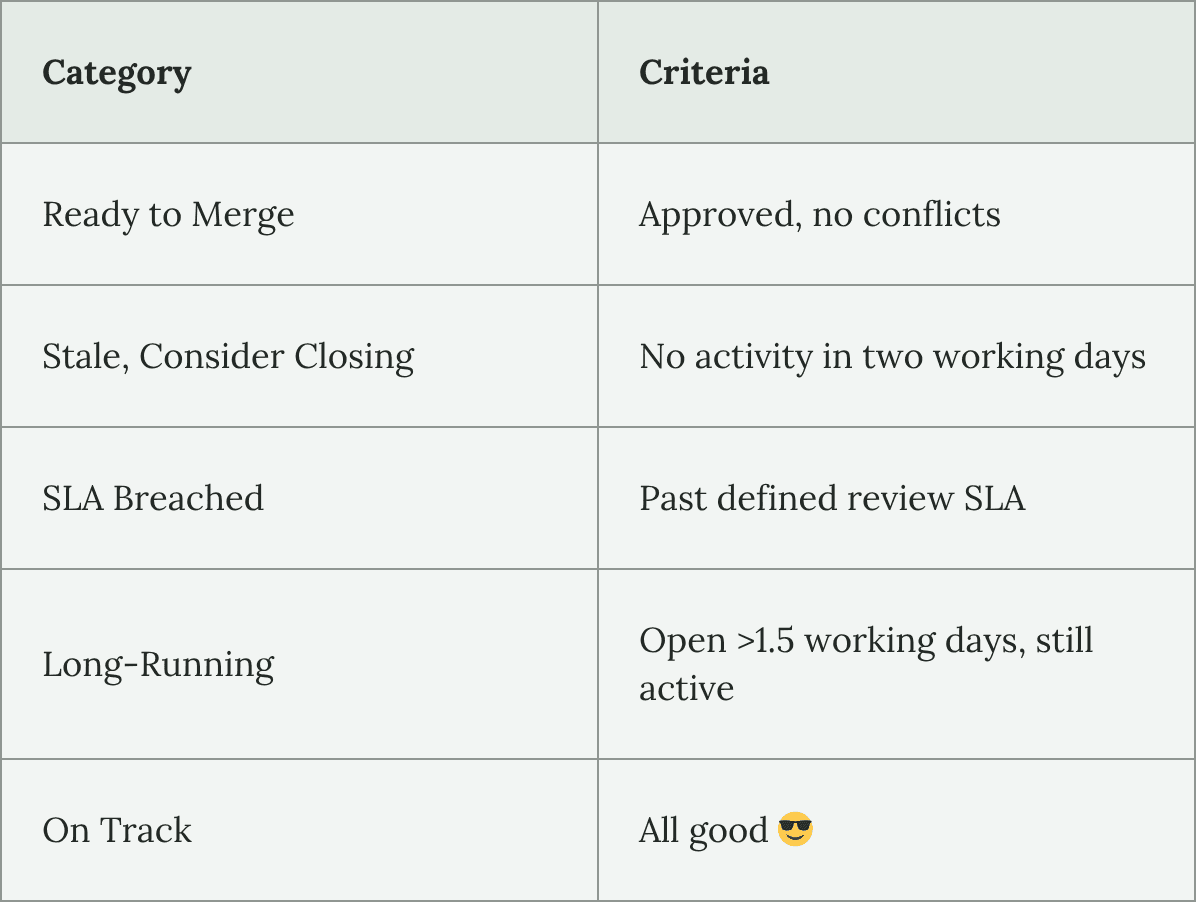
It posts a digest to the relevant Slack channel, timed to natural interruption points in people’s days (first thing in the morning, just after lunch).
PRs in the Post-Claude World
Reviewing AI code is weird, and that’s fine. It would be weird if it wasn’t. Bugs aren’t really the issue. The code that Claude pumps out is generally pretty correct. The hard part is structural.
Claude doesn’t reuse existing patterns by default. If there’s a utility in the codebase that does roughly what’s needed, a human engineer would usually find it and use it, maybe twist it or extend it to fit the new scope. Claude will often write a perfectly parallel version, tailored to the idiosyncrasies of its current task instead. The new code isn’t bad per se, but it’s different. The resulting diff is larger because it introduces new functions instead of leaning on existing stuff. More importantly, the cognitive diff is wasteful.
You also lose some of the texture of the code. In every codebase I’ve shared over the years, I could usually tell which one of my colleagues had written a class or function. We all have little quirks and preferences that show up in the code we write. It’s like handwriting. You learn the patterns, build up a predictive model in your head, and it makes the code easier to navigate.
Claude doesn’t have this. It writes TypeScript like the average of every TS dev in the world, shaped by the prompt and context provided to it by the user. The lack of predictable patterns means that the code can be more difficult to understand at a glance.
So we have two new jobs as reviewers (I know they’re not really new, but the emphasis has changed):
Check that we’re using what we already have
Defending the codebase against entropy
The usual stuff (correctness, security, performance) is still there, but the default failure modes are different now. The dominant problems aren’t implementation bugs; they’re scope and design issues at the start of the process, and subtle coherence issues that show up over time.
Which is why we’re spending more time on scope and design reviews these days. Nailing the scope early keeps us honest and saves time in the design stage. Taking time at the design step saves us time trying to decipher what Claude has produced at the PR step. “Writing is cheaper than coding” has turned out to be even more true when you’re working with something that can write code faster than you can read it.
How does it feel?
There’s a weird, almost perverse tension at the centre of using codegen tools. Writing code with Claude Code is genuinely really fun. The conversational interface makes it feel like I’m delegating work to some kind of omniscient machine spirit that only cares about doing what I ask of it. It makes my little monkey brain feel suuuuper nice. It’s an infinite loop of instant gratification dopamine hits.
Reviewing someone else’s 800-line diff isn’t fun. It never has been. It’s hard, cognitively taxing work, and AI tooling didn’t change that.
What changed is the gap between coding and review. The pull toward writing code over reviewing is stronger than it was last year. It would be dishonest to pretend otherwise.
Team agreements help, but the pull hasn’t gone away yet. For now, it’s a practice that we have to work on every day.
Where we are now
We’re getting there. I’m not going to sit here and pretend that we alone have solved this problem. But we’re trying to face it with intellectual honesty. We’ve tightened up our dev practices, and have become more disciplined engineers. Throughput is higher than when we started using Claude. Our review queue is shrinking. PRs are getting more pleasant. They come with the context of the scope and design documents, framing and verification instructions. We’re not hitting all our review SLAs yet, but we’re getting closer every week.
The fixes I’ve described are our current best bets. If they don’t work, we’ll do something else. The team is durable. The specific solutions are disposable.
The key thing is that we’ve realised that productivity doesn’t look like creating PRs; it looks like getting useful code into users’ hands.