All articles
Vision
·
·
0
min read
AI isn’t coming for your job; it’s coming for your YAML

In my previous life, before joining Ewake as a founding engineer, I worked at a tech giant (the one with the bridge for a logo).
Big Tech companies have a luxury that early-stage startups don’t: a unified, top-down platform. When you operate at that scale, you can mandate that every engineer uses the same logger, the same metric naming convention, and the same deployment pipeline. Entire teams exist purely to maintain that alignment.
It’s comfortable inside the walled garden.
But out here in the wild, production environments are diverse. And by diverse, I mean they are a mess.
The real challenge is that every company’s infrastructure evolves differently over time, and traditional software has always solved that problem with configuration.
At Ewake, we are building an AI production teammate. The goal isn’t to give engineers more buttons to click; it’s to provide a partner that lives in your stack, understands your infrastructure, and handles the “first look” when something goes wrong.
But like a human teammate, an AI still needs to be onboarded. And while most companies use familiar tools (things like Datadog, GitHub, and Slack) the way they use those tools varies wildly.
Customer A logs everything as structured JSON, cares deeply about P99 latency, and wants root-cause analysis with a code fix suggestion.
Customer B dumps unstructured text logs, ignores latency entirely, and just wants a Slack message saying “Rollback” or “Don’t Rollback.”
To scale, you want standardisation. But to be useful, you have to support the messy reality of how people actually work.
And that’s where things get tricky.
The Combinatorial Explosion
Traditionally, the software engineering answer to “every customer is different” is configuration.
You build a settings page. Then you add a toggle for log format. Then a dropdown for notification style. Then a regex field so customers can map their internal service names.
I call this Configuration Hell.
Every new toggle increases the possible state space of your system. Your clean, opinionated backend slowly turns into a Rube Goldberg machine of if/else statements. Testing becomes harder, because no one can reproduce the exact combination of settings that Customer C happens to be using.
But the real problem appears after you ship.
Once configuration becomes complex enough, you’re forced into an uncomfortable choice:
Diabolical UX You expose the full control panel to customers. They stare at a cockpit of YAML files, regex patterns, and nested options, realise it will take weeks to integrate, and quietly abandon the product.
Accidental Consultancy To prevent that churn, your engineers jump on onboarding calls and write the configuration for them. Suddenly your scalable SaaS product starts behaving suspiciously like a high-priced consulting business.
Neither outcome scales.
To build an AI teammate that actually works across different environments, we had to stop asking customers to configure the system and start building software that figures out the configuration itself.
The Rigidity Trap
Traditional software is rigid. It’s a deterministic set of instructions that executes exactly as written.
That rigidity is normally a strength. Deterministic systems are predictable, safe, and easy to reason about.
But they rely on one assumption: that the world they interact with is predictable.
Production environments aren’t.
Context matters enormously.
A 500ms latency spike on a high-frequency trading system is catastrophic. The same spike on a background image processing job is completely normal.
You can encode those distinctions in a rule engine, but only by adding more and more configuration. Eventually you’re back in Configuration Hell.
In other words, you’re trying to solve a fuzzy human problem with rigid logic.
Enter the Fuzzy Logic Layer
If you want software to interpret messy operational context without requiring endless configuration, you need a system designed to reason about ambiguity.
You need a Large Language Model.
But if you just pipe a log dump into a standard LLM prompt and ask for a summary, you get a parlour trick. Debugging production is never a single-shot question. It requires a reasoning loop. An on-call engineer doesn’t just look at an error spike and instantly know the answer; they look at a Datadog graph, form a hypothesis, query GitHub for recent PRs, and then make a decision.
That is why we didn’t just wrap an LLM in a UI. We built an Agent. By giving the model the autonomy to iteratively query databases, evaluate the response, and pull secondary context before making a routing decision, we aren’t just summarizing data — we are automating the investigative workflow.
Now, at this point, any experienced SRE reading this is probably rolling their eyes — and fairly so. Agents are probabilistic systems. They hallucinate. Letting one run freely inside a production environment would be irresponsible.
But we realised something important: the probabilistic part of the system doesn’t have to execute anything.
It only has to interpret.
At Ewake, the Agent acts as a Semantic Investigator. It sits between the messy, unstructured reality of production systems and the deterministic tools engineers rely on.
The fuzzy logic lives in interpretation and routing. The rigid logic stays in execution.
That separation turns out to be extremely powerful. Here is a high-level look at how it works:
Navigating the Data Sprawl
Consider a simple Error 500 alert.
In traditional automation systems, retrieving useful context requires explicitly coded integrations and mapping logic:
If database lock appears → check recent ORM commits → query deployment logs → correlate metrics.
But production environments rarely follow predictable patterns. Logs may be structured or unstructured. Engineers might discuss an issue in a Slack thread long before it appears in monitoring dashboards.
An Agent can ingest all of that information directly: logs, pull requests, alerts, and conversations. It interprets relationships across different data formats without requiring engineers to explicitly encode every mapping rule.
The goal isn’t to eliminate integrations entirely. Systems like Datadog or GitHub still provide the raw data.
What the Agent replaces is the brittle logic layer that normally tries to stitch those systems together.
The Handshake: Forcing Structure on the Probabilistic
Of course, you can’t just drop a probabilistic model into production infrastructure and hope for the best.
The challenge is forcing a system that speaks natural language to behave safely inside a deterministic platform.
Our solution is a two-layer guardrail system: Shape and Sanity.
Layer 1: Shape (Structured Outputs)
When the Agent decides on an action — for example, querying Datadog for recent error logs — it isn’t allowed to respond with free-form text.
Instead, it must produce a strictly structured output defined by a schema. We use utilities like Zod to enforce that structure, leveraging the schema descriptions to pass explicit instructions to the model.
Imagine the input for a simple log-retrieval tool:
If the LLM tries to return a conversational paragraph, or hallucinates a generic date instead of a strict ISO timestamp, the validation catches it and rejects the payload automatically. This ensures our deterministic code never has to interpret natural language when it expects a strictly typed API payload.
Layer 2: Sanity (Qualitative Validation)
Structured outputs solve the syntax problem, but not the truth problem.
An LLM can still confidently fabricate a service name that fits the schema perfectly.
To catch that, we run qualitative validation using evaluation tools in our agent framework, Mastra. These evaluators compare the Agent’s output against the original context to detect hallucinations or unsupported claims.
If the evaluation fails, the output is rejected and the system retries with adjusted reasoning.
In practice, this creates a controlled loop:
Probabilistic reasoning → structured output → validation → deterministic execution.
Press enter or click to view image in full size
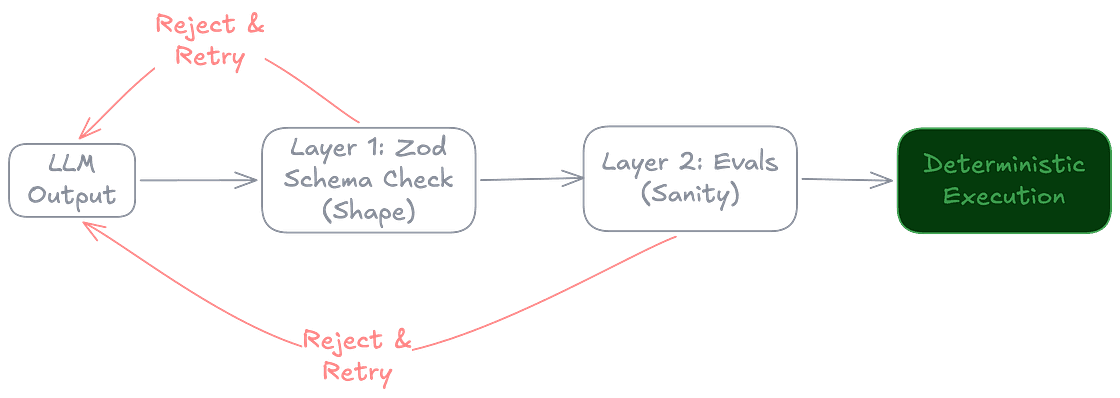
Only validated outputs are allowed to trigger downstream actions.
The 60-Second Trade-off
There’s another objection engineers raise immediately: latency.
LLMs are slow. An Agent investigating an incident might take close to a minute to ingest logs, review recent pull requests, and generate a structured summary.
In traditional software, 60 seconds is a lifetime.
But in incident response, 60 seconds is about how long it takes an on-call engineer to wake up, find their glasses, and open Slack.
By the time they start reading the alert, the Agent may already have scanned thousands of log lines, correlated recent commits, and highlighted the most likely anomaly.
Trading a minute of machine time to save half an hour of human investigation is usually a very good deal.
Learning From the Mess
There’s another important side effect of this architecture: it allows us to learn from our mistakes.
Every time the Agent misclassifies an alert, the validation layer records the failure. Every time an engineer confirms or rejects the Agent’s investigation, that feedback becomes part of an evaluation dataset.
Over time, this produces something extremely valuable: a corpus of real production incidents and their resolutions.
Rather than relying forever on general-purpose foundation models forever, we can use that dataset to fine-tune smaller, faster models specialised for production debugging.
In other words, the system doesn’t just investigate incidents. It gives us the ability to learn from them.
The Economics of Laziness (and On-Call Sanity)
Of course, none of this would matter if engineers couldn’t trust the system during an outage.
For that reason, our Agent is deliberately constrained.
It is not an autonomous operator. It is an investigator.
Read-only by default. The Agent gathers context and proposes explanations, but it doesn’t trigger rollbacks or deploy fixes automatically.
Deterministic observability. Every prompt, context window, and tool call is internally logged. If the Agent makes a bad inference, we can trace exactly what information it saw and where the reasoning went wrong.
The goal is simple: reduce Mean Time to Insight, not automate every action.
During an outage, the hardest problem isn’t running a command. It’s figuring out which command to run.
Conclusion: It’s Still Just Plumbing
We didn’t build this architecture because we wanted to ride the AI hype cycle.
We built it because the alternative was spending years writing configuration logic for every strange observability setup in the wild.
The real engineering challenge over the next few years isn’t training slightly smarter foundation models. It’s building the systems that safely integrate probabilistic reasoning into deterministic infrastructure.
Agents give us a practical way to do that.
They let us replace thousands of brittle configuration rules with a system that can interpret messy environments directly, while still keeping execution inside a deterministic safety cage.
It’s not a digital super-brain. It’s just a fuzzier if statement for a messy world.
Ewake isn’t coming for your job; it’s coming for your YAML. And compared to maintaining another 5,000-line YAML configuration file, that’s a trade-off we’re happy to make.